Le Machine Learning est l’une des principales technologies de l’Intelligence Artificielle (IA). Cet article vous propose un état des lieux des approches de Machine Learning et des plateformes et outils actuellement disponibles dans ce domaine.
Le Machine Learning et sa place dans l’IA
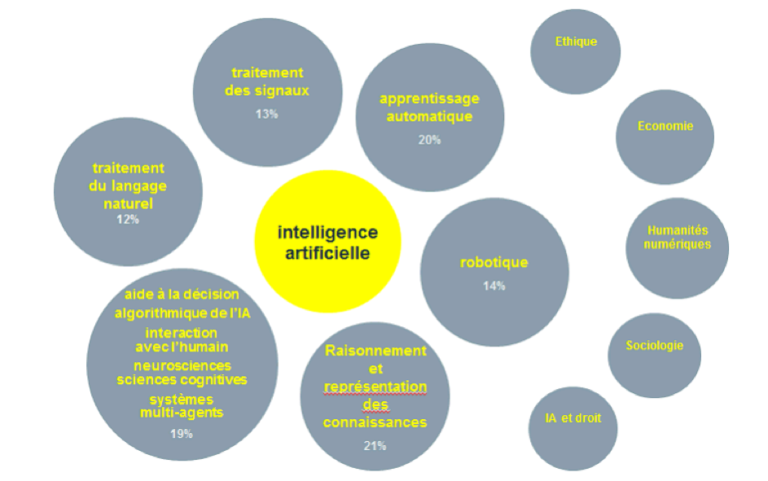
Dans leur rapport au Sénat en mars 2017 (synthèse du rapport), le député Claude de Ganay et la sénatrice Dominique Gillot retiennent six grands domaines pour définir l’intelligence artificielle, en lien étroit avec cinq domaines des sciences humaines et sociales (partie droite du graphique ci-dessous) :
L’apprentissage automatique (« Machine Learning » en anglais) est l’un des principaux domaines de l’intelligence artificielle. Il permet de réaliser des programmes informatiques, accomplissant des tâches difficiles à programmer par des moyens traditionnels (ou bien au prix d’un effort, d’une expertise et d’un temps bien plus important). L’idée est de concevoir des algorithmes capables d’apprendre à trouver eux-mêmes une solution, soit à partir d’exemples déjà résolus (apprentissage supervisé), soit en récompensant chaque progression de l’algorithme vers une solution satisfaisante (apprentissage par renforcement).
Les différents types de Machine Learning
Le Machine Learning consiste à construire un algorithme qui utilise directement des données représentatives du problème que l’on cherche à résoudre. En conséquence, les différents types de Machine Learning correspondent aux manières d’utiliser ces données pour « apprendre à la machine » à résoudre un problème.
Elles se distinguent principalement par le niveau de supervision de l’apprentissage, et/ou la manière de récompenser la progression de l’apprentissage vers une bonne solution. Nous avons dressé ci-dessous une liste des principales typologies :
→ Apprentissage supervisé (supervised)
On présente à l’algorithme des exemples de la tâche à réaliser, où sont fournies à la fois les entrées (des images par exemple) et les sorties (résultats) souhaitées (par exemple voiture, avion, etc.). Le but de l’algorithme de Machine Learning (réseaux de neurones, SVM – machine à vecteurs de support, etc.) est alors de rechercher une règle générale qui fait correspondre les entrées aux sorties.
Le cas général de l’apprentissage supervisé est adapté lorsque l’on connait le résultat attendu pour un grand nombre de données d’entrée. Plus les modèles sont complexes, plus la quantité de données nécessaires pour obtenir de bons résultats est grande.
En fonction des données disponibles pour l’apprentissage, on pourra utiliser des versions dérivées de l’apprentissage supervisé telles que celles présentées ci-dessous :
- Apprentissage semi-supervisé (semi-supervised) : l’ordinateur ne reçoit qu’un signal d’apprentissage incomplet. Pour une partie des exemples, les entrées sont disponibles mais les sorties sont manquantes.
- Apprentissage actif (active) : l’ordinateur ne peut obtenir la sortie que pour un nombre limité d’entrées (basé sur un budget) et doit optimiser son choix des exemples pour lesquels il demande d’acquérir la sortie. L’apprentissage se déroule de manière interactive, les exemples étant présentés à l’utilisateur pour être étiquetés.
- Apprentissage par renforcement (reinforcement) : les données d’entraînement (sous forme de récompenses et de punitions) ne sont données qu’à titre de rétroaction aux actions du programme dans un environnement dynamique, comme la conduite d’un véhicule ou le jeu contre un adversaire. Un exemple de ce type d’algorithme est le Q-Learning.
→ Apprentissage non supervisé (unsupervised)
Cette méthode se distingue de l’apprentissage supervisé par le fait qu’il n’y a a priori pas de connaissance des sorties attendues. Dans l’apprentissage non supervisé, il y a comme entrée un ensemble de données collectées. Ensuite le programme traite ces données comme des variables aléatoires et construit un modèle de « densités jointes » pour cet ensemble de données. L’algorithme doit découvrir par lui-même la structure plus ou moins cachée des données.
Voici deux exemples de méthode d’apprentissage non supervisé :
- Le clustering pour identifier dans un ensemble de données, des sous-populations présentant des caractéristiques proches. Cette méthode permet par exemple d’identifier des groupes de personnes au sein d’un échantillon.
- L’auto-encodeur correspond à la capacité à construire une représentation intermédiaire des données d’entrée, équivalente mais de plus petite dimension, et permettant de générer, à partir de cette représentation un résultat aussi proche que possible des données sources.
Exemple : à partir d’un ensemble d’images HD couleur (1082x920x3~=3 millions de valeurs), on construit un réseau de neurones qui, pour chacune des images, fournira une représentation sous la forme de X valeurs (1000 par exemple) permettant de reconstruire une image la plus proche possible de l’original. Cette méthode peut être utilisée pour la compression d’images (on ne transfère plus que les 1000 valeurs au lieu des 3 millions), mais cette méthode peut aussi avoir d’autres usages. En effet, pour compresser l’image, le réseau va devoir chercher à « interpréter » le contenu de l’image, et donc identifier des caractéristiques propres à celles-ci. Ces caractéristiques sont utiles pour la classification d’images, on pourra donc utiliser le modèle appris via un auto-encodeur (sur des images non étiquetées), pour le réutiliser dans l’apprentissage d’un classifieur d’images.
→ Apprentissage par transfert (transfer)
L’apprentissage par transfert peut être vu comme la capacité d’un système à reconnaître et appliquer des connaissances et des compétences apprises à partir de tâches antérieures sur de nouvelles tâches ou domaines partageant des similitudes. Les questions qui se posent alors sont : comment identifier les similitudes entre la ou les tâche(s) cible(s) et la/les tâche(s) source(s) ? Comment transférer la connaissance de la/des tâche(s) source(s) vers la/les tâche(s) cible(s) ?
Nous avons donné un exemple de transfert dans la description de l’auto-encodeur, mais cette technique s’applique à bien d’autres cas. Elle permet souvent de pallier le faible nombre de données disponibles pour un problème donné, en utilisant les résultats obtenus avec des problématiques proches.
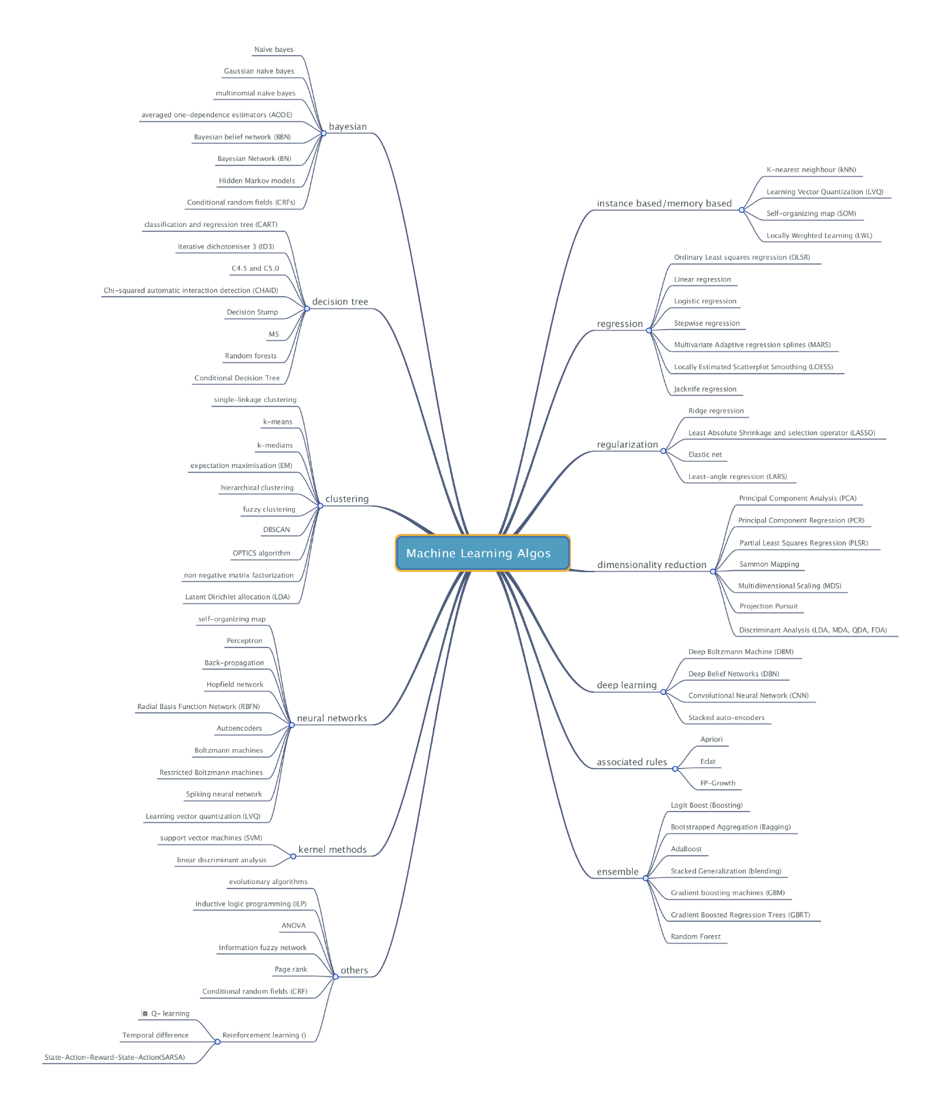
Pour une vision plus complète des méthodes de Machine Learning, voici une carte mentale construite par l’IRT SystemX :
Les applications du Machine Learning
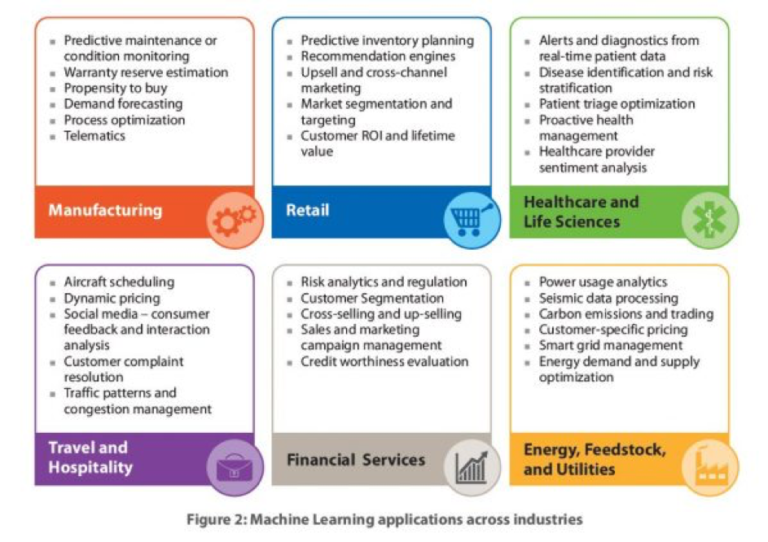
Avec l’informatisation de la plupart des processus dans les entreprises, de nombreuses données reflétant l’activité de l’entreprise, de ses employés et de ses clients sont générées. Ces données contiennent les « règles » ou les « équations » régissant ces processus : on peut donc envisager d’automatiser certaines tâches en utilisant ces données comme exemples d’apprentissage. On trouve donc des applications du Machine Learning dans quasiment tous les secteurs, comme l’atteste le diagramme ci-dessous issu d’un blog du 4 juin 2016 du magazine économique américain Forbes.
{kind=link}
Comment mettre en œuvre le Machine Learning ?
Pour développer une application basée sur du Machine Learning, il faut trois éléments principaux :
→ Des données
Comme le principe de ces applications est d’utiliser des données servant d’exemples pour l’apprentissage, il est indispensable de disposer de telles données, qui peuvent être notées ou non, en fonction du problème posé (supervisé ou non). On distingue les données servant à l’apprentissage, pour construire le modèle, de celles servant à l’évaluation de la performance du modèle. Dans tous les cas, on préfère utiliser des données réelles, mais dans certains cas, celles-ci ne sont pas suffisantes. Il est donc nécessaire de générer des données synthétiques pour compléter les données réelles.
→ Des algorithmes
Les méthodes d’apprentissage automatique sont mises en œuvre par des algorithmes qui s’appliquent aux données au travers d’outils informatiques (hardware et software). On distingue plusieurs types d’outils :
- ceux qui permettent de stocker et structurer les données (fichiers, bases de données, solutions Big Data),
- ceux qui permettent d’appliquer les algorithmes sur les données pour construire des modèles (réseau de neurones, random forest, etc.),
- ceux qui permettent d’évaluer leurs performances et mettre en production des modèles (plateformes de Machine Learning).
La plupart des environnements disponibles permettent d’utiliser conjointement ces deux types d’outils.
→ De la connaissance et du savoir-faire
Comme tout outil, il faut disposer du mode d’emploi avant de mettre en œuvre une méthode de Machine Learning. Le domaine étant très actif, les méthodes et outils évoluent très vite. Il est indispensable de se documenter pour se tenir à jour des dernières avancées. Les bonnes pratiques se trouvent en consultant régulièrement des publications scientifiques, les benchmarks, les tutoriels et les MOOC en ligne, ou bien en participant ou en organisant des hackathons et des challenges.
Où trouve-t-on les données ?
Lorsque l’on travaille sur un projet, les premières sources de données sont celles fournies par le projet (par exemple des données de trafic routier ou de consommation d’énergie). Néanmoins, il est souvent nécessaire de compléter les données privées disponibles dans le projet par d’autres données (par exemple, les données météo sont de bons facteurs explicatifs du trafic routier ou de la consommation d’énergie). De nombreuses plateformes dites Open Data (et des moteurs de recherche dédiés) permettent de rechercher et télécharger ces données externes aux projets, disponibles gratuitement ou devant être achetées. Ces plateformes permettent aussi de publier ses propres données (avec l’accord des commanditaires), et ainsi d’augmenter leur visibilité et de profiter du résultat de la recherche ouverte appliqués à ces données.
Dans certains cas, la quantité et la diversité de nos données privées – éventuellement augmentées par des données externes – restent insuffisantes. Il faut alors envisager de générer des données synthétiques, les plus réalistes possible. Bien que ce problème soit récurrent, on ne trouve pour l’instant que peu d’outils génériques ou de plateformes de génération de données.
Comment gérer les données pour le Machine Learning ?
Nous avons expliqué dans les paragraphes précédents que la donnée était au cœur des méthodes de Machine Learning. Un élément à prendre en compte est donc le stockage et la gestion de ces données pour mettre en œuvre ces méthodes correctement.
La gestion des données pour le Machine Learning doit répondre à plusieurs problématiques.
→ Comment collecter les données ?
Les données brutes – publiques ou privées – sont rarement exploitables directement, les travaux suivants sont souvent nécessaires pour obtenir des résultats pertinents :
- le nettoyage des données pour éviter l’apprentissage de comportements non souhaités,
- l’étiquetage des données pour définir le résultat attendu de l’apprentissage,
- la qualification des données pour estimer leur représentativité.
De plus, cette collecte peut être effectuée ponctuellement, ou résulter d’un processus de flux avec une arrivée constante de nouvelles données. Certaines plateformes mettent à disposition tout un ensemble d’outils et/ou d’infrastructures pour simplifier ce processus.
→ Comment stocker les données ?
Une fois collectées ces données doivent être stockées, et là encore le stockage va dépendre de la typologie de données collectées et de la phase du projet (développement/exploitation).
En fonction de la typologie des données, il est possible d’utiliser des fichiers (par exemple des images ou bien fichiers binaires propres aux frameworks utilisés) pour des données homogènes. Par contre, si les données sont nombreuses et variées, il est préférable d’avoir recours à des bases de données.
Concernant le déploiement, les algorithmes de Machine Learning s’insèrent dans les systèmes d’information au même titre que d’autres composants, avec un accès aux data warehouses (entrepôts de données) et aux data lakes (méthode de stockage des données utilisée par le Big Data).
Dans tous les cas, on conserve l’historique des données et traitements associés dans la phase de développement (cahier de laboratoire) et l’exploitation (gestion de configuration).
Où trouve-t-on les algorithmes ?
Pour mettre en œuvre les algorithmes de Machine Learning, il n’est plus nécessaire de les programmer. De nombreux outils sont disponibles sous la forme de librairies, de framework ou de plateformes, le plus souvent sous forme de logiciel libre.
Il est néanmoins possible de distinguer trois manières de mettre en œuvre ces algorithmes :
→ L’installation d’outils « in premises » : par exemple scikit learn, tensorflow, pytorch, R
Les logiciels sont installés directement sur le PC du Data Scientist ou sur un serveur auquel on lui donne un accès pour travailler à distance. Ces outils nécessitent la connaissance d’un langage de programmation (majoritairement Python, mais d’autres langages sont disponibles) pour définir les modèles à utiliser, injecter les données, et piloter les phases d’apprentissage.
→ Des plateformes Cloud (MLaaS) : Azure ML, Watson, Google, Amazon
Ces plateformes permettent de mettre en œuvre des algorithmes de Machine Learning via des applications web déployées sur le Cloud. Ces plateformes sont souvent dédiées à une typologie de données.
→ Des environnements hybrides : Dataiku, OpenML
Ces plateformes peuvent être utilisées comme des services (MLaaS) ou déployées dans un environnement.
Le Machine Learning s’avère donc être une branche de l’intelligence artificielle prometteuse, porteuse de nombreuses évolutions technologiques dans de nombreux domaines sociétaux et industriels. Afin de soutenir son développement, de nombreux outils sont aujourd’hui à disposition :
- Des plateformes de mise à disposition de données ont été créées, telles que gouv.fr, le Machine Learning Repository de l’UC Irvine, ou encore OpenDataSoft. Ces sources de données externes peuvent être utilisées dans des projets de R&D en complément des données privées.
- Des plateformes et/ou environnements de développement : nous citerons par exemple Amazon Machine Learning, Dataiku, SciKit-Learn et Tensorflow + Keras, pytorch.
Des plateformes de connaissance, pour développer son expertise autour des méthodes de Machine Learning via des MOOCs, des tutoriels mis à disposition en ligne et des publications scientifiques.
Plutôt que de décrire les technologies et algorithmes sous-jacents au Machine Learning, nous avons présenté dans cet article les spécificités de cette nouvelle approche par rapport aux méthodes analytiques[1] plus classiques de la science informatique.
La pertinence des solutions à base de Machine Learning est très dépendante des connaissances métier (pour la formulation et l’identification du problème que l’on souhaite résoudre), des données associées (à partir desquelles le Machine Learning pourra être effectué) et de la structure du modèle utilisé pour les traiter à partir des outils disponibles (le métier des spécialistes en Machine Learning). A cette fin, nous avons partagé un vocabulaire et une compréhension des enjeux pour faciliter les collaborations entre « expert métiers » de cas d’usage et spécialistes du Machine Learning.