
{kind=link}
L’utilisation de la simulation numérique dans l’industrie se heurte à plusieurs limites, telles que la difficulté à modéliser certains phénomènes physiques ou bien le coût de calcul qui peut être très élevé. Dans ce contexte, l’Intelligence Artificielle (IA) s’est imposée comme une piste prometteuse pour y faire face et permettre une utilisation plus efficace des simulateurs physiques dans la prise de décision. Dans cet article, nous nous intéressons aux défis associés à la mise en place des simulateurs physiques augmentés par l’IA, et nous discuterons les enjeux liés à leur validation pour un déploiement industriel.
Simulation numérique et apprentissage : une démarche classique de l’hybridation
La simulation numérique représente aujourd’hui un outil indispensable dans la conception et le pilotage des systèmes physiques complexes, grâce notamment à son coût relativement faible par rapport aux essais réels réalisés directement sur le système à concevoir. Par le passé, de nombreuses applications industrielles ont pu bénéficier des apports de la simulation pour améliorer les performances des systèmes physiques. Cependant, durant les dernières années, les simulations numériques font face à une complexité grandissante des systèmes physiques à modéliser et doivent évoluer afin d’intégrer de plus en plus de disciplines avec des périmètres applicatifs variés. Dans certains cas, les phénomènes physiques peuvent être difficiles à modéliser ou peuvent donner naissance à des modèles numériques demandant un temps de calcul très élevé, ce qui rend difficile le recours à la simulation numérique pour une prise de décision en milieu industriel.
Pour faire face à ces limites, de nombreux travaux de recherche dans le domaine du calcul scientifique ont proposé des méthodes numériques ad hoc afin d’améliorer le compromis coût/précision des simulations numériques. Ces travaux ont offert à l’industrie plusieurs approches, largement utilisées aujourd’hui, pour faire face au coût de calcul important des simulateurs physiques. Nous pouvons citer les méthodes de réduction de modèles (ROM) et les modèles de substitution (appelés aussi surface de réponse, ou modèles surrogate).
L’idée de base de ces méthodes repose sur la création d’un modèle appris à partir des données simulées qui se substituera au solveur physique, cher à calculer. Ces techniques restent cependant adaptées à des problèmes physiques relativement simples et mono-disciplinaires et peinent à résoudre des cas plus complexes comme par exemple les problèmes aux grandes dimensions ou les problèmes inverses.
Simulation numérique et apprentissage profond : la promesse d’une révolution
Durant les dix dernières années, un engouement particulier a été observé pour l’utilisation de techniques d’apprentissage basées principalement sur des architectures de réseaux de neurones profonds. Les avancées spectaculaires qu’a connu ce type de méthodes dans d’autres domaines applicatifs comme la reconnaissance d’images ou le traitement automatique du langage naturel (NLP) a fortement motivé les chercheurs de la communauté du calcul scientifique à explorer leur potentiel apport dans la simulation physique. Grâce à des architectures complexes de réseaux de neurones, ces méthodes se sont avérées prometteuses avec plusieurs hybridations réussies rapportées dans la littérature. Outre ce gain important et non-négligeable, l’apprentissage profond a aussi permis de faire émerger de nouveaux champs applicatifs qui n’existaient pas auparavant avec les approches classiques d’apprentissage comme les réseaux antagonistes génératifs (GANs) [2], le transfert de connaissances entre deux modèles via les techniques de transfer learning [3], l’apprentissage du processus d’apprentissage lui-même avec les techniques de méta-learning [4], etc.
La démocratisation de ce type d’approches pour une utilisation industrielle se heurte néanmoins à plusieurs limites parmi lesquelles les deux des plus importantes sont sans conteste le coût de l’obtention des données d’apprentissage et la validation des simulateurs ainsi « augmentés ».
Le coût de la génération/obtention de données physiques
Les phénomènes physiques complexes requièrent souvent des réseaux de neurones de très grande taille pour être correctement appréhendés, ce qui nécessite le recours à des volumes de données très importants pour la phase d’apprentissage. Bien que cela soit possible en utilisant des données simulées générées à partir d’un solveur physique, l’utilisation exclusive des données réelles pour entraîner un réseau de neurones profond s’avère aujourd’hui une tâche difficile en raison des quantités limitées d’échantillons disponibles. Il est important de noter que même pour des données simulées, le coût de génération peut représenter un frein pour réaliser un apprentissage de qualité, surtout pour les données précises obtenues avec des simulations physiques fines (comme le 3D par exemple).
La validation des simulateurs physiques augmentés
La question de la validation des systèmes prédictifs a toujours été considérée comme un défi important, et cela dès l’apparition des premiers travaux d’intelligence artificielle. En 1950, Alain Turing posa les premières briques d’une démarche pour évaluer la faculté d’une machine à bien imiter le raisonnement humain avec le test dit « de Turing » [1]: « Si un Humain n’est pas capable de dire lors d’une conversation lequel de ses interlocuteurs est un ordinateur, alors on peut considérer que l’ordinateur a passé avec succès le test ».
Depuis, plusieurs travaux de recherche se sont intéressés à cette question et plusieurs approches et critères ont été proposés dans la littérature, permettant d’aboutir à une démarche plus au moins standardisée aujourd’hui. Cependant, le constat de base en ce qui concerne la modélisation physique reste clair : il n’existe pas aujourd’hui une approche permettant de valider formellement un résultat issu d’un simulateur physique augmenté par l’IA. Il est à noter que les simulateurs physiques classiques (non-augmentés) bénéficient tout de même d’une démarche de validation avec des critères très largement utilisés comme les bornes d’erreurs ou la vitesse de convergence. Cela ne doit pas pour autant créer un frein pour l’utilisation de l’IA pour hybrider les modèles physiques, car le manque à gagner serait considérable, vu le succès observé dans d’autres domaines.
Dans le même temps, une autre approche de cette question de validation peut se trouver dans le fait de considérer l’IA comme étant une discipline expérimentale à part entière, comme la biologie par exemple. Dans ce contexte, l’expérimentation, l’étude comparative et surtout la reproductibilité des résultats deviennent les ingrédients de base pour une évaluation efficace des modèles physiques appris, sans toutefois apporter de possibilité de certification, indispensable pour les systèmes critiques.
Le benchmarking pour valider les simulateurs physiques hybrides
Compte tenu des challenges décrit dans la section précédente, nous nous sommes focalisés au sein du projet HSA (Hybridation Simulation apprentissage) [5] du programme IA2 (Ingénierie Augmentée et Intelligence Artificielle) [6] sur la problématique de validation expérimentale des simulateurs physiques augmentés. Dans ce cadre, nous avons proposé une méthodologie outillée de benchmarking générique et modulaire pour couvrir les différentes étapes de développement de simulateurs physiques augmentées.
Cette méthodologie est en cours d’évaluation sur plusieurs cas d’usages industriels du projet HSA, décrivant des domaines physiques hétérogènes et variés (mécanique des solides, mécanique des fluides (CFD), simulation acoustique, simulation électrique, simulation thermique). L’objectif derrière cette démarche est d’obtenir une plateforme consolidée qui permettrait à la communauté du calcul scientifique d’intégrer de nouveaux cas d’usage physique facilement. La méthodologie proposée (illustrée ci-dessous) s’articule autour de trois modules principaux qui représentent aussi les trois étapes principales dans la mise en place d’un simulateurs physique augmenté :
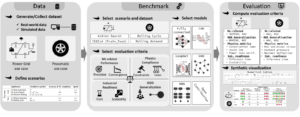
1- Gestion de données. Durant cette étape l’utilisateur doit définir l’ensemble des données relatives au phénomène physique étudié. Nous distinguons deux types de données : les données réelles (issues des essais physiques, collectées sur le terrain) et les données simulées générées à partir d’un solveur numérique. Nous devons définir aussi l’ensemble des scénarios physiques que nous souhaitons couvrir durant l’étude en répondant principalement aux questions : quel est le phénomène physique étudié ? quels sont les variables d’entrée ? quelles sont les observables ?
2- Benchmarking. L’utilisateur sélectionne les scénarios et les ensembles de données concernés par son étude, ainsi que les méthodes d’apprentissage choisies pour entrainer le modèle physique, et qui seront comparées par la suite sur la base des critères d’évaluation. Pour mener à bien la phase d’apprentissage, nous nous interfaçons avec les plateformes déjà disponibles dans l’état de l’art et offrons un choix important en termes d’architectures de réseaux de neurones. Il est à noter que nous pouvons considérer aussi d’autres méthodes d’apprentissage classique et d’autres modélisations physiques pouvant servir de points de repère pour les comparaisons.
3- Évaluation. Une fois les modèles appris, l’utilisateur doit évaluer les résultats obtenus par les différentes méthodes d’apprentissage. Pour cela nous avons proposé un ensemble de critères définis spécifiquement pour les simulateurs physiques augmentés, tout en prenant en considération les aspects liés au passage à l’échelle en contexte industriel. Ces critères sont regroupés en quatre catégories principales: les critères statistiques liés à l’apprentissage, les critères de généralisation OOD (out of distribution), les critères liés au respect des lois physiques (comme par exemple : loi de conservation de la masse, loi de Joule, loi d’Ohm, etc.), et enfin les critères de maturité pour la mise en œuvre industrielle.
Durant les dernières années, l’hybridation de la simulation physique par les techniques d’IA, et plus précisément par les techniques d’apprentissage profond, s’est installée progressivement comme une piste de recherche prometteuse. L’objectif étant de renforcer davantage le rôle de la simulation numérique en milieu industriel, notamment dans la prise de décision lors des différentes phases de cycle de vie des systèmes physiques complexes. Les premiers travaux menés au sein du projet HSA de l’IRT SystemX se sont attaqués à la problématique de validation des systèmes physiques hybrides et ont permis d’établir une démarche de benchmarking générique qui a été appliquée avec succès sur deux cas d’usage industriels différents. Une attention particulière a été accordée à l’applicabilité des méthodes hybrides en milieu industriel, afin de faciliter leur utilisation pour résoudre des problèmes physiques du monde réel. Les travaux en cours et futurs viseront à élargir le spectre des applications en intégrant de nouveaux cas d’usages industriels, en profitant du cadre collaboratif offert par le projet HSA. Cette démarche permettra de consolider l’approche proposée et d’offrir à la communauté de calcul scientifique un outil qui serait capable d’intégrer facilement de nouvelles applications physiques hybrides.
Références
[1] Turing, A. M. (2009). Computing machinery and intelligence. In Parsing the turing test (pp. 23-65). Springer, Dordrecht.
[2] Creswell, A., White, T., Dumoulin, V., Arulkumaran, K., Sengupta, B., & Bharath, A. A. (2018). Generative adversarial networks: An overview. IEEE signal processing magazine, 35(1), 53-65.
[3] Zhuang, F., Qi, Z., Duan, K., Xi, D., Zhu, Y., Zhu, H., … & He, Q. (2020). A comprehensive survey on transfer learning. Proceedings of the IEEE, 109(1), 43-76.
[4] Hospedales, T., Antoniou, A., Micaelli, P., & Storkey, A. (2021). Meta-learning in neural networks: A survey. IEEE transactions on pattern analysis and machine intelligence, 44(9), 5149-5169.
[5] https://www.irt-systemx.fr/projets/HSA/
[6] https://www.irt-systemx.fr/programmes-de-recherche/ia2