
{kind=link}
Le machine learning est aujourd’hui omniprésent. Il transforme peu à peu l’industrie et notamment le marché des voitures autonomes. Au sein de cet article, nous expliciterons la notion de voiture autonome, dans le but d’identifier les méthodes existantes pour les faire fonctionner. L’enjeu est primordial : comprendre les liens entre l’apprentissage de la conduite par des machines et la compréhension humaine, tant sur l’aspect sémantique que sur l’aspect factuel.
Qu’est-ce qu’une voiture autonome ?
Les voitures autonomes s’apprêtent à bouleverser nos déplacements et notre gestion du trafic routier. Il convient donc d’en dresser une définition. Jusqu’à récemment, une définition unanime n’avait pas encore été approuvée par l’ensemble des acteurs internationaux, tant sur le plan technique (en termes de méthodes d’apprentissage), que sur le plan juridique (en termes de responsabilités et de législation routière), ou même géographique (en termes de dépendances entre les deux précédents points et selon le pays). Un consensus récent a cependant vu le jour, définissant divers niveaux d’automatisation , lesquels nous permettent non seulement d’entrevoir l’avenir mais également de situer l’avancement des recherches.

Le rapport du véhicule avec ce qui l’entoure et la manière qu’il peut avoir de réagir aux événements qui se déroulent autour de lui sont des enjeux primordiaux pour l’instauration d‘une confiance de la société envers cette innovation. Le fonctionnement d’une voiture autonome peut être décrit comme suit : le véhicule perçoit son environnement, planifie son trajet puis infère le trajet en fonction des informations des capteurs. Il y a donc trois sous-composantes : la perception, la planification et le contrôle. Il est alors possible d’entrevoir le rôle primordial que pourrait jouer la donnée, puisqu’elle semble être à l’origine la base d’apprentissage nécessaire à la prise de décision du véhicule autonome au sein de cette chaîne de traitement. Une question importe : comment se servir du machine learning dans ce cas ?
La question du machine learning en conduite autonome
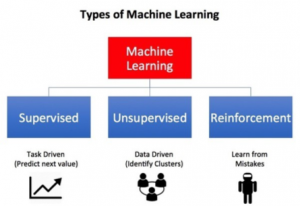
Le machine learning, y compris sa variante récente deep learning, est un sous-domaine de l’intelligence artificielle. Il est possible de distinguer plusieurs types d’apprentissages adaptés à un secteur applicatif particulier. Dans le transport autonome, on se concentre sur l’apprentissage supervisé et celui par renforcement, mais ces deux derniers ne se basent pas du tout sur le même paradigme théorique.
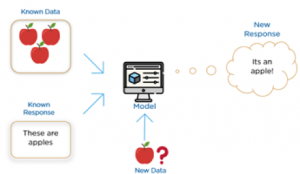 En apprentissage supervisé, la donnée est prépondérante. Cette dernière est labélisée (chaque donnée possède une description), et le système apprend simplement à relier un ensemble de caractéristiques observées à un label. Si nous cherchons à reconnaître quel fruit se trouve sur une image, chaque donnée pourrait décrire la circonférence et la couleur du fruit, et on connaîtrait déjà la typologie de chacune de ces entrées.
En apprentissage supervisé, la donnée est prépondérante. Cette dernière est labélisée (chaque donnée possède une description), et le système apprend simplement à relier un ensemble de caractéristiques observées à un label. Si nous cherchons à reconnaître quel fruit se trouve sur une image, chaque donnée pourrait décrire la circonférence et la couleur du fruit, et on connaîtrait déjà la typologie de chacune de ces entrées.
Le système pourrait ensuite être capable de conclure la nature du fruit à chaque nouveau duo de circonférence et de couleur qu’on lui donnerait. L’explosion du deep learning a d’ailleurs rendu ces tâches beaucoup plus simples qu’auparavant et les réseaux de neurones sont maintenant au cœur des méthodes utilisées. Dans le cas des voitures autonomes, la perception identifierait un panneau de signalisation et des données sur la vitesse par exemple et prendrait une décision sur l’accéleration à appliquer ou sur le fait de freiner, en fonction de cette information.
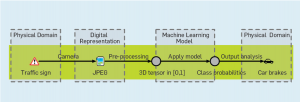
Bien que de nombreux modèles apparaissent et sont fonctionnels, nous restons dépendants de la donnée. De grandes quantités de ces dernières sont nécessaires pour obtenir une représentativité suffisante des situations. Sans données variées, la voiture pourrait faire face à une situation qu’elle n’a jamais rencontrée . Il serait donc intéressant de pouvoir jouer sur les données différemment pour se rapprocher de l’intelligence humaine, pour aller au-delà de cet apprentissage par l’association. Mais comment faire ?
Un paradigme différent face aux données
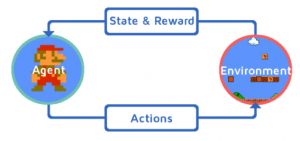
L’apprentissage par renforcement pourrait être considéré comme un modèle de théorie des jeux, à la croisée de nombreux domaines allant de l’informatique aux neurosciences en passant par la psychologie. En effet, un agent agit sur un environnement au moyen d’actions. Ce dernier lui renvoie une récompense, qui est la première clé du renforcement. Nous déduisons de la connaissance à partir des observations passées et nous souhaitons maximiser la récompense à travers le temps. La donnée n’est plus le socle, mais constitue une interaction avec l’agent en décrivant l’environnement après une action ! Les équations de Bellman permettent alors de formaliser la prise décision et la maximisation de la récompense.
Comment savoir si une action fut le meilleur choix ? C’est le principe d’exploration/exploitation qui constitue la seconde clé du renforcement. Imaginons que notre environnement soit constitué de deux portes qui se trouvent face à nous. La première nous offrirait une petite somme constante à chaque fois qu’on l’ouvrirait, tandis que la seconde nous offrirait un immense trésor mais seulement à de très rares ouvertures de cette dernière. Il nous faudrait alors trouver le bon équilibre. L’agent risquerait de considérer la première porte comme étant la plus intéressante, mais la seconde mériterait de ne pas complètement être délaissée : l’exploration de ce que nous ne connaissons pas, face à l’exploitation des éléments connus de l’environnement.
Le renforcement utilise des modèles tels que les réseaux de neurones, plus connus pour leur utilisation dans l’apprentissage supervisé, pour des problèmes où l’apprentissage se fait avec des données pour lesquelles on ne connaît pas réellement la réponse attendue au premier abord. En effet, le principe d’exploration/exploitation énoncé plus haut implique une modification constante des entrées et des actions possibles, ce qui va à l’encontre des modèles supervisés qui ont ce besoin en données labélisées. Par l’utilisation de plusieurs astuces, on se retrouve pour certaines méthodes dans une situation similaire au supervisé et les réseaux de neurones sont alors en mesure d’être utilisés de manière stable. Ces derniers ont une finalité différente de ce que l’on peut rencontrer habituellement. Il faut donc relier le modèle, l’algorithme en somme, et la formulation du problème dans lequel on se trouve.
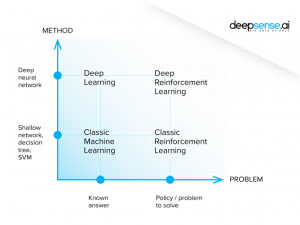
Si l’on revient à notre cas d’usage, l’environnement serait donc la route autour de notre véhicule, ce dernier prenant des actions dans cet environnement qui lui renvoie des récompenses selon les actions prises. Il s’agit donc d’un apprentissage par l’erreur, comme si le modèle raisonnait pour éviter de prendre de mauvaises décisions au fil du temps. Le nombre de portes devient cependant gigantesque, et plusieurs problèmes, déjà énoncés pour certains, apparaissent :
- l’apprentissage est souvent complexe, le modèle met du temps à se stabiliser,
- l’espace des actions et résultats possibles est énorme dans le cas des voitures autonomes,
- les entrées et sorties dont le système se sert pour apprendre changent constamment, puisque l’environnement est dynamique.
On entraîne le plus souvent les systèmes de renforcement dans des simulateurs réalistes pour veiller à étudier leurs comportements avant d’imaginer pouvoir les mettre en production pour le monde réel, compte tenu des problèmes énoncés. Après la perception et la représentation des données qui en découle, la prise de décision en renforcement pourrait aller plus loin que celle étudiée via les méthodes supervisées : l’intelligence artificielle capable de raisonner, la clé pour que les voitures autonomes soient définitivement une réalité et se rapprochent du raisonnement humain, capable de moduler ses décisions en fonction de l’environnement qui l’entoure.
Entre extraction de connaissances et raisonnement, combiner le meilleur des différents mondes pourrait donc permettre à l’être humain de voir sa vison du transport révolutionnée. Comme un pas de plus vers l’intelligence artificielle généralisée, les voitures autonomes sont au cœur des préoccupations puisque la technique rencontre ici un système critique, qui nécessite une mise en relation directe de son efficacité avec les biais humains qu’elles se doivent d’outrepasser.
Il reste encore de nombreuses travaux à effectuer, la recherche et l’industrie s’intéressant de plus en plus au renforcement comme l’avenir du domaine, et potentiellement sa sécurisation, enjeu majeur du déploiement de ces technologies.
Vulgarisation d’excellente qualité!!
Il eut été intéressant d’ajouter quelques uses case d’applications : capteurs, système de décision.